
Powerpoint was definitely a revolution for presenting academic papers. After several conferences researchers know how to prepare presentations that can communicate their ideas and concepts to the audience and at the same time keep them captivated. The same holds for posters. There are a lot well known tricks about how to make a poster that successfully passes the message. It is true though that a lot of researchers don’t follow the guidelines for preparing successful posters and presentations properly, but we will deal with that on a different post.
In our recent workshop at MLTrain@NIPS about reproducible research, we asked the authors of the papers to present the code of their paper so that the audience can understand the necessary details for coding the algorithms and reproducing the results. This was the first time that we attempted a workshop like that and we would like to summarize the lessons we learned about presenting reproducible research.
Writing code in a presentable way
Creating a python notebook that demonstrates the code is as hard as writing the paper. It might actually be even more difficult since it requires some software engineering skills that are not known to researchers. In this section we discuss techniques that can help in presenting the code of the paper.
Synthetic datasets
In every software project, unitests play a major role. Their intention is to prove that the code works according to the assumptions and the expectations. Every algorithm described in a paper has some assumptions that are usually reflected on the properties of the dataset. For every algorithm there exists a dataset that is giving optimal results. As it is often difficult to find a real dataset that satisfies this properties, it is very important to create synthetic datasets that are optimal for the algorithm. Synthetic datasets have some other advantages too.. For example they can be relatively small and simple so the training time can be reasonable for demonstration purposes. Also several parameters can be controlled and show how they can break the algorithm. Our next steps is to formalize a set of synthetic datasets for different tasks. In fact instead of creating the datasets we would rather create generators.
Why would somebody take the extra time to write the code in a presentable way?
If you have read freakonomics, you probably remember that economics is the science of incentives. So the question is what is the incentive for a researcher to spend extra time to write code that demonstrates the reproducibility of her/his results? The researchers are basically evaluated on the number of their publications weighted by the importance of the publicing authority (conference, journal, etc). It would be very difficult to convince tenure committees, or PhD committees to change their evaluation process. It is true though that the research impact from each of us is judged upon the usage of the algorithms we produce. Very often research groups open source software of the research in an effort promote usage. Usually these efforts fail because the academic groups lack software engineering skills. Even if they have good software engineers, they are gone after graduation and they are not able to continue supporting and maintaining the projects.
I argue that a better strategy would be for the research groups to create educational material about the code of their papers that will allow industry people to understand and implement the algorithms in a more maintainable and robust way. We need some good use cases to prove this hypothesis.
Another way to promote reproducible research is to actually create a credible organization that will accept submissions with strict reviews. There has been a precedence in this direction with the distil.pub magazine. Distil hosts graphically and interactively rich articles written mainly in javascript. These articles require a lot of effort to produce, but the authors receive prizes that are highly respected by the community. Following that paradigm might be a good way to go.
The role of a python notebook
Python notebook is a great tool for combining graphics and code. The code can be broken in segments and visualizations of intermediate variables and results can be presented. It is not advisable to throw all the code in one notebook. Most of the papers have require lengthy code for manipulating the data and for the computations. The notebook must present only the important aspects that are either tricky to code. Coding the paper by translating the pseudo code is probably not that difficult. Coding though efficiently, in a scalable manner requires some experience and it should be demonstrated.
While notebooks are great, they are not platform independent. Code usually comes with dependencies that is not always easy to configure. For that reason work has to be done on standardizing the demo platform (Amazon SageMaker, Microsoft Notebooks).
The X-Ray of an algorithm
When somebody studies the 4-stroke engine it is really useful to see images like the following one. These are cross section (tomographic or x-ray) pictures. They are very informative and at the same time give local and global view of the operation of the engine. We wish to create views of the algorithms in the same way. The way to achieve something like that is by introducing several probes (tensorboard) in the code. It is also important to introduce switches that turn on and off different components and loops. This is something that makes the easy to first debug several aspects of the algorithm. It also makes it possible to understand the importance of every component.
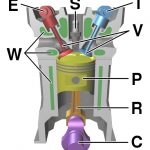
Conclusion
Presenting the code of an algorithm resembles a lot the debugging and unit-testing process. It requires a lot of code commenting and modularity. Apart from visualizing variables and intermediate results with the appropriate probe, it is also necessary to create switches that turn on and off segments of the code. Of course this is not enough, it also requires a well documented manual that will explain what each switch mean and how to conduct the experiments. It would be great if this process can be templatized and get enhanced with some automation tools, so that it becomes relatively easy for authors to submit usable code. Till then we have to work on incentives for authors to take the extra step.